A colleague of mine recently reached out to ask me a question about Azure AI Search that I didn’t know about as I’ve been so busy with my recent project that I haven’t been able to continue my AI development hobby projects that I used to find time for. Those who know me will know that if you ask me about a problem I’m interested in, my curiosity will drive me to determine what the solution is so I thought I’d write a quick blog post about this.
So the question that I was asked is why did deleted blobs in a Storage Account that is indexed with Azure AI Search is still returned. With this in mind, I quickly set up a test environment with the following resources:
- Azure AI Service
- Azure OpenAI Model
- txt-embedding-ada-002
- Storage Account
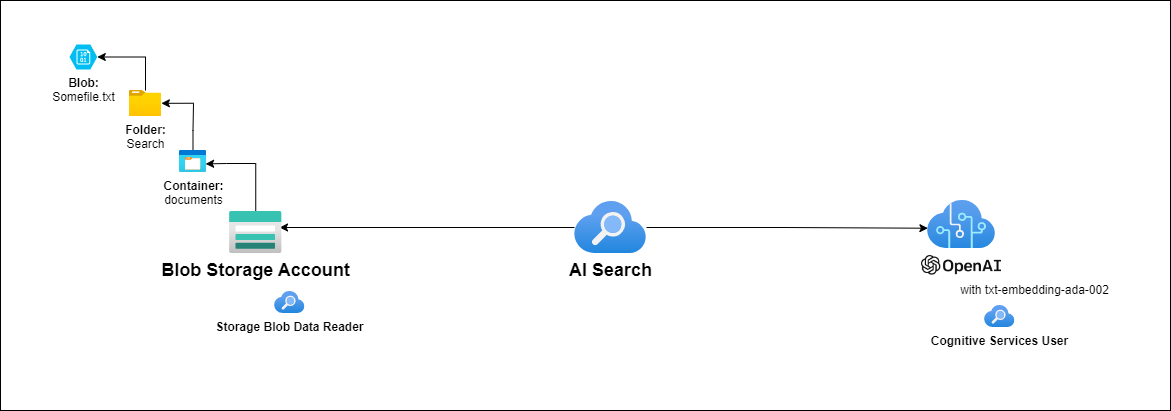
The set of files I used for this test is a set of plain text files that contain brief descriptions of a set of Azure resources:

I won’t be demonstrating the steps for setting up the indexing but I’ll paste the screenshots of the relevant resource configuration:


With the single file uploaded and indexed, the first test is to ensure that it is returned from search queries and the easiest way to do this is navigate into the Indexes and use the search bar as such:
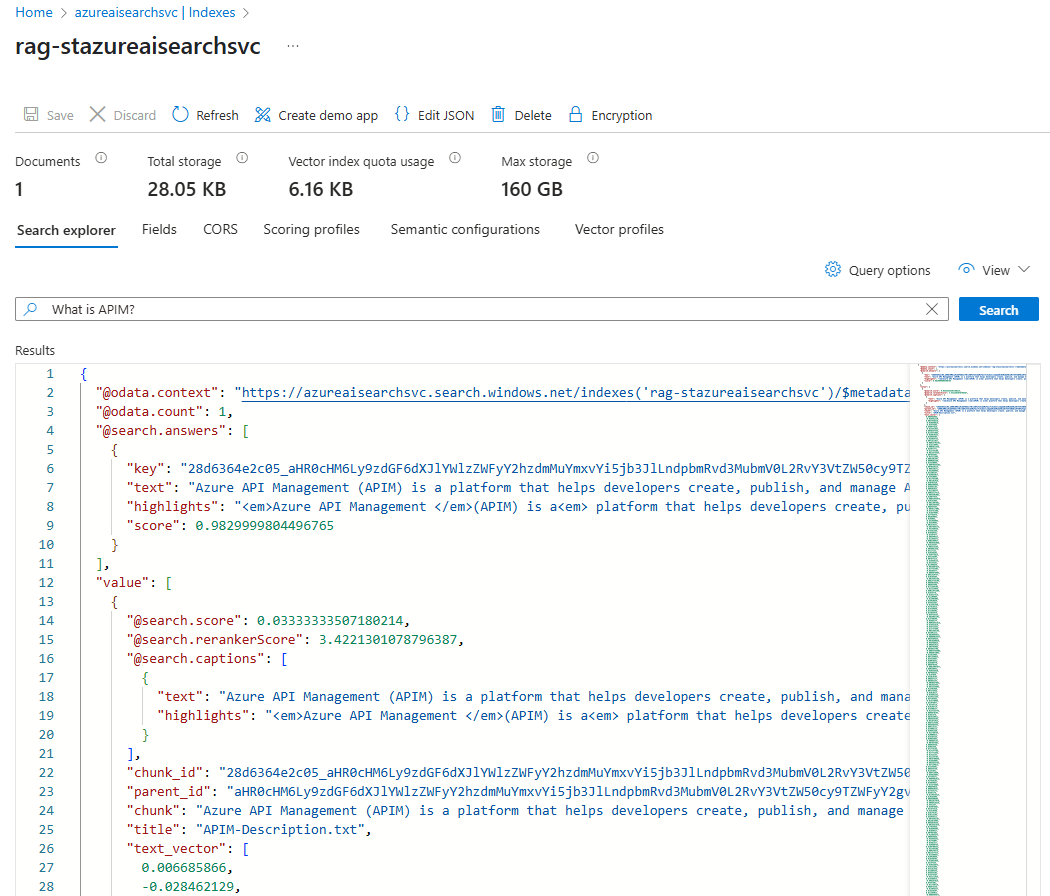
Another way to test this is with Postman and I wanted to take this opportunity to answer another question I received a while back in reference to a previous blog post where I demonstrated how to call APIs of AI Search to determine whether a file was indexed:
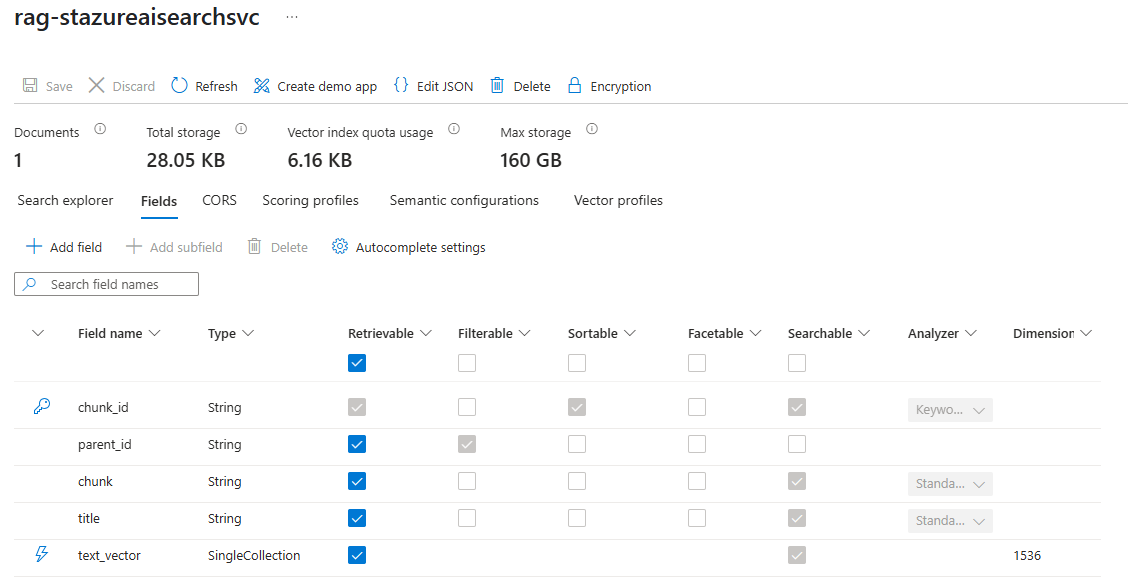
In this post, I used the title field in the index to determine where a file is indexed by AI Search:

What I noticed was that this new setup I created still had the title field but the Filterable checkbox was now greyed out:
I’m not sure why this has changed as I’ve used the Import and vectorize data functionality in AI Search plenty of times the year before without this behavior but to quickly get around this is to recreate the index with the JSON modified.
Begin by navigating into the Index and click on the Edit JSON button:
Copy the contents of the JSON into a text editor of your choice, as these are the settings of the existing Index:

Now proceed to delete the index:

Now proceed to edit the JSON content and locate the block representing the title field and update the filterable value from false to true:

Copy the contents and recreate the index with the update:

With the new index created, you should now see the filterable is enabled:

Proceed to run the Reset (very important) and then rerun the indexer:


With this out of the way, I will set up Postman to use the use a POST request that allows you to specify contents in the body to determine whether a file with the specified file name was indexed by the indexer. The post method format is outlined as follow:
POST https://[service name].search.windows.net/indexes/[index name]/docs/search?api-version=[api-version]
Content-Type: application/json
api-key: [admin or query key]
The title field in the index represents the full file name and extension of the file that has been index. To test this with Postman, we would configure a POST call specifying the filter where title equals the file name of the document:
https://azureaisearchsvc.search.windows.net/indexes/rag-stazureaisearchsvc/docs/search?api-version=2024-07-01

Now that we have a document indexed and confirmed searchable, let’s proceed to try and delete the file from the Storage Account and search for the document again:
After the blob is deleted, the following behavior are observed with the AI Search results:
- Attempting to search for this blob in AI Search will reveal that the results are still returned.
- Attempting to rerun the indexer will also show that the results are still returned.
- Attempting to run a reset only will also show that the results are still returned.
- Re-running the indexer after a reset will show that the results are still returned.
This obviously poses an issue as it doesn’t look like there is an easy way to remove this document from the AI Search indexed results.
Microsoft has official documentation around this in the following documentation:
Change and delete detection using indexers for Azure Storage in Azure AI Search
https://learn.microsoft.com/en-us/azure/search/search-howto-index-changed-deleted-blobs?tabs=portal
The document outlines that change detection only picks up new and changed documents and not deletion. Microsoft’s proposed method of tracking deleted documents to avoid orphaned files is to implement a soft delete strategy that results in deleting search documents first, then followed by physical deletion in the Azure Storage account. The proposed 2 methods to address this is as follow:
- Native blob soft delete that only applies to Blob Storage (this is why I used a Blob storage account rather than Data Lake) – Currently in Preview as of May 17, 2025)
- Soft delete using custom metadata
What’s important to note is that both of these methods must be applied from the very first indexer run as if you decide to implement it on an existing indexer, any documents that were deleted before the policy is configured will remain in the index even if the indexer is reset. The suggestion is to create a new index using a new indexer.
The document provides a wealth of information as to how delete detection works and I encourage you to read it from start to finish as my summary may leave some details out and
For the purpose of this blog post, I will demonstrate using the Native blob soft delete rather than the custom metadata method (I may write a follow up post on that when I have time).
Let’s start with the requirements:
- Blobs must be in an Azure Storage container and not ADLS Gen2 or Azure Files
- Soft delete must be turned on for blobs
- Document keys for the documents in your index must be mapped to either be a blob property or blob metadata, such as “metadata_storage_path”
- You must use a preview REST API such as 2024-05-01-preview, or the indexer Data Source configuration in the Azure portal, to configure support for soft delete
- Blob versioning must not be enabled in the storage account. Otherwise, native soft delete isn’t supported by design.
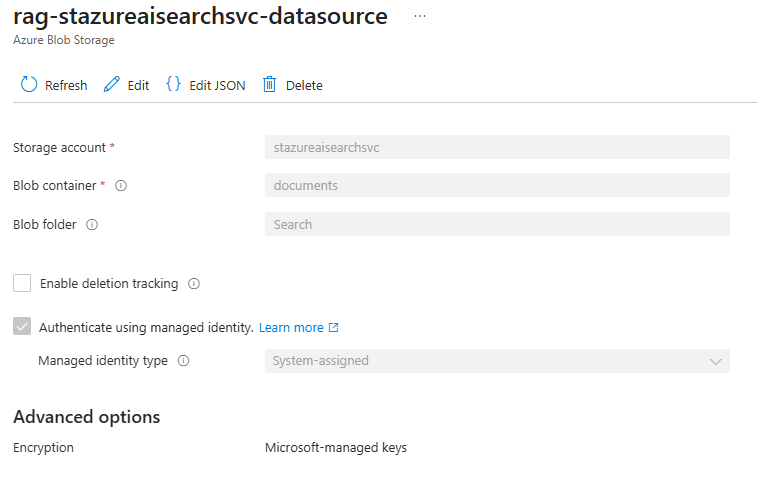
As per the documentation, the first step in enabling this is to configure your data source with Track deletions and Native blob soft delete enabled. You would have seen this while going through the Import and vectorize data wizard:

What I noticed while testing with my existing AI Search is that you can actually enable this on an existing data source in AI Search:
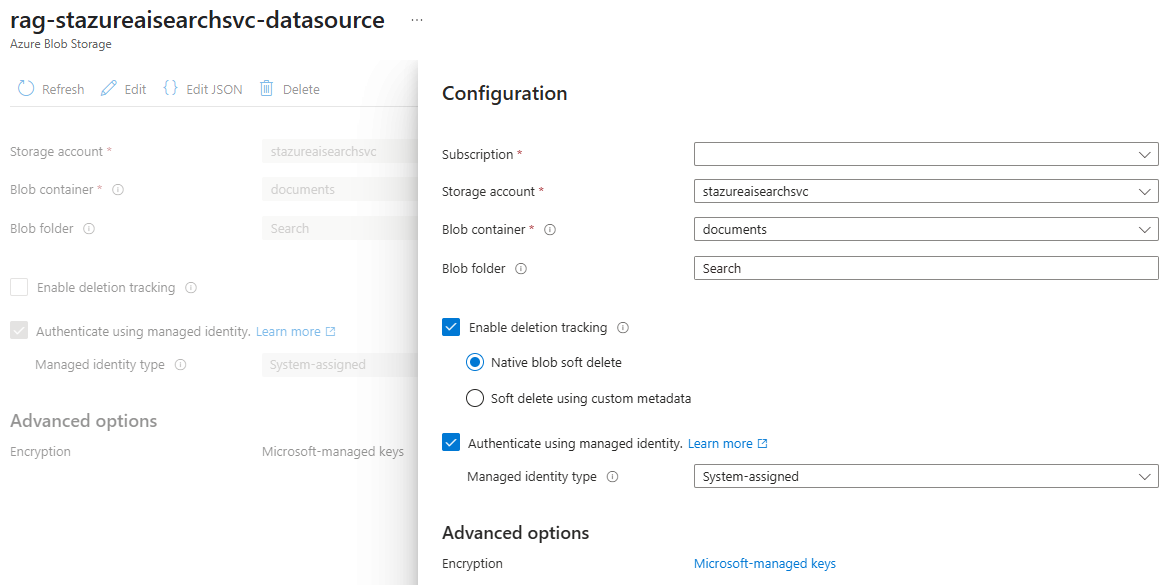
Clicking on the Edit button allows you to enable the feature:
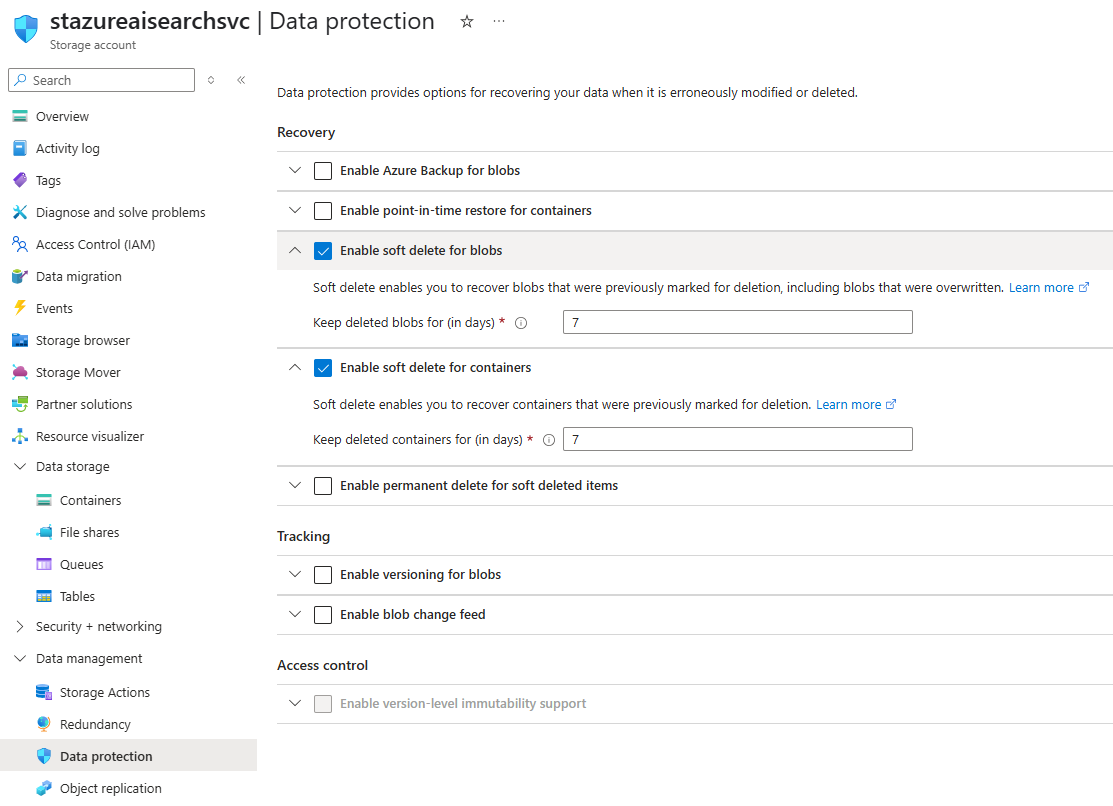
As it is usually the default configuration when creating the storage account, double check that soft delete is enabled:
With this configuration ready, let’s try re-uploading the same file we deleted, run the indexer, delete the file, and try searching again:

What I’ve noticed is that the Docs succeeded after the upload and indexer run will show a count of 1:
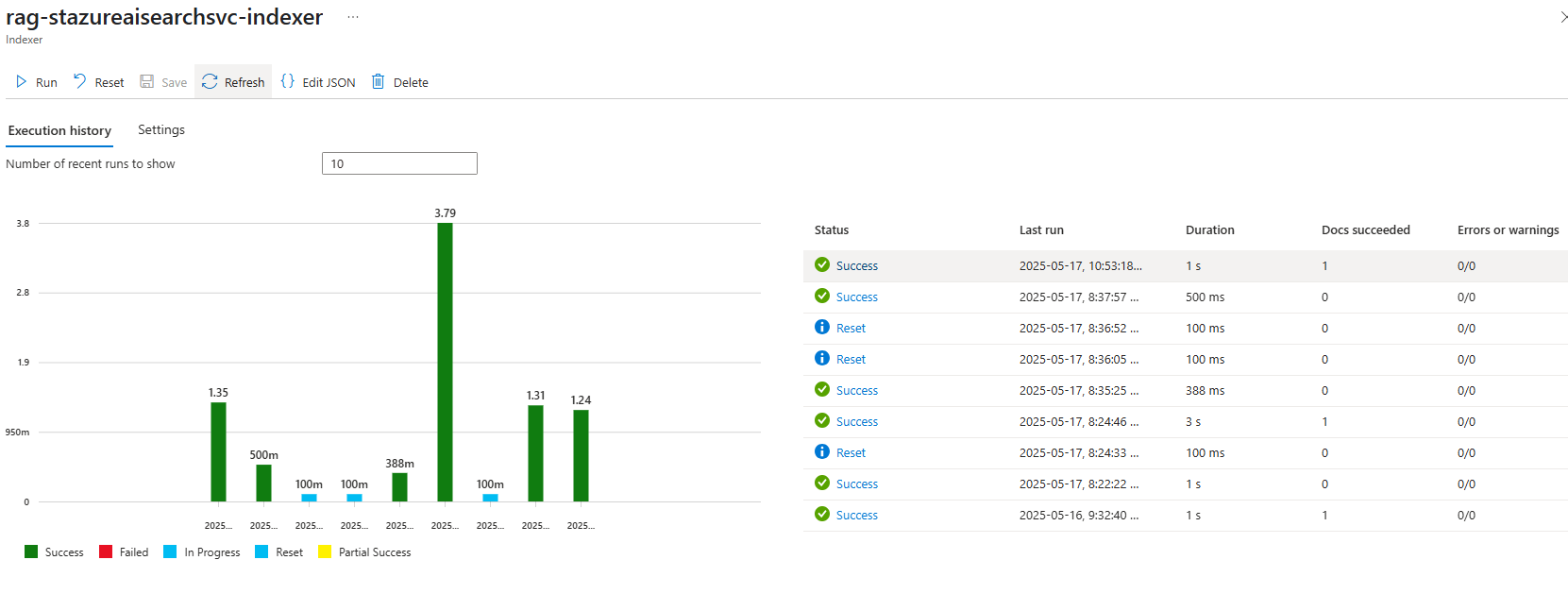
The results from proceeding to delete and run the indexer again will show Docs succeeded with a count of 1 again:

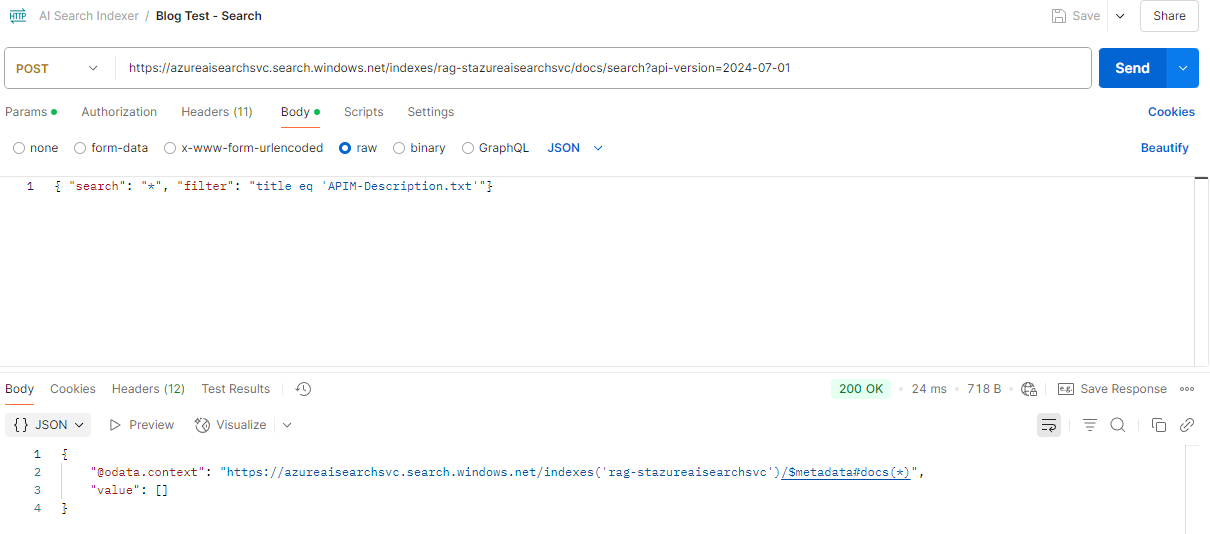
Oddly enough, the document no longer shows up in my Postman call, which goes against what the documentation states that the data source and indexer should be recreated:
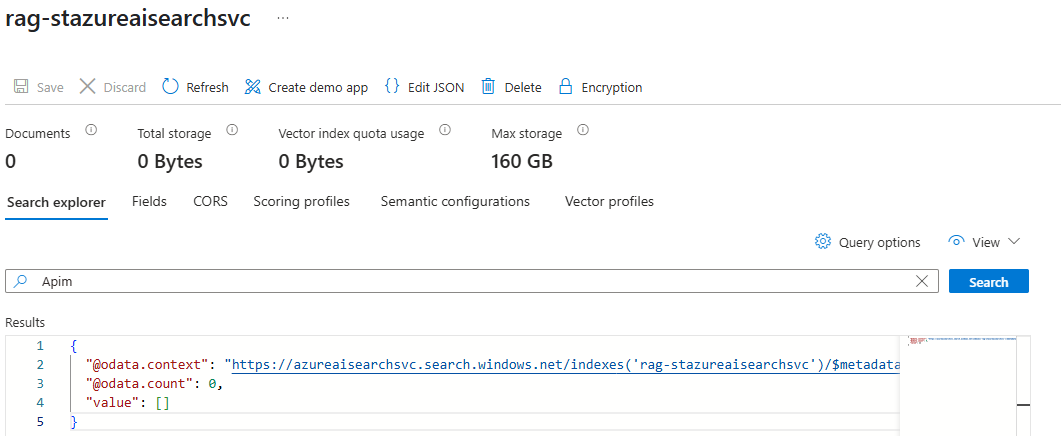
Using the search feature for the indexes yield the same result with the document no longer returned:
I’m not completely sure as to why delete detection is working even though I had not recreated the data source and indexer and suspect maybe the continuously improvements Microsoft developers are making may remove this requirement. In any case, I always recommend going with what the documentation states and if it suggests that the data source and indexer should be recreated, then it should be followed.
Hope this helps anyone who might be looking for a quick demonstration of how to get AI Search to remove deleted blobs that are index so information that is meant to be removed do not end up being returned in searches.

